Writing subqueries is an important skill to develop if you want to work effectively with your database resources.
EXAMPLES
One of the first subqueries you will probably write will be within the where statement to limit results.
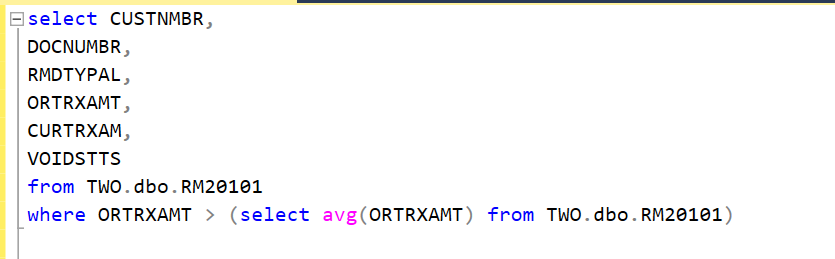
If you need to display the value used to filter you can use a subquery within your select statement. Here we calculate the field ‘avgamt’ using a scalar subquery, i.e. it will return the same value on every line.
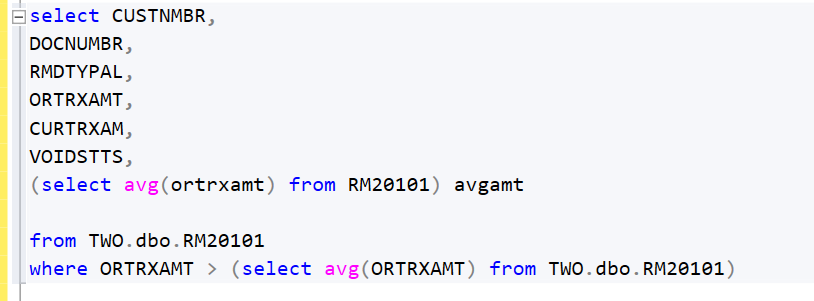
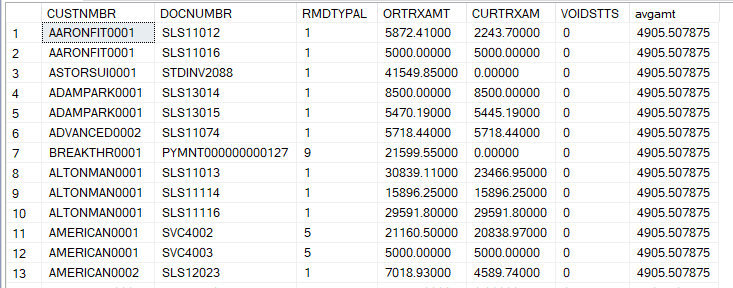
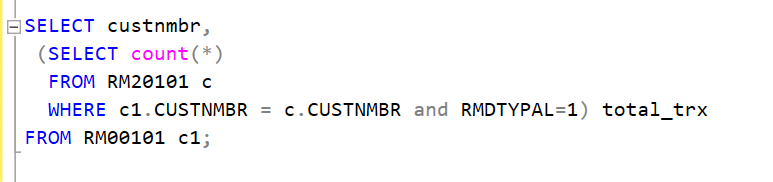
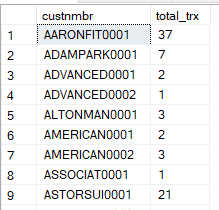
A correlated subquery is one of your more complex query structures. Here we have a subquery within our select statement that uses a value returned by the main query to the customer master table to count the number of invoices. The field ‘total_trx’
Understanding how to write effective subqueries is the first step in automating custom processes in your database. Managing transaction lists in your system, automated archiving and monthly sales reporting become much easier when writing subqueries in SQL become second nature.
If you’re interested in learning more about scalar subqueries, multiple row subqueries, and correlated subqueries check out this page.
To speak to an expert about your reporting headaches email [email protected].